今回の記事はこれまでの理論記事で紹介した競馬予測に関する知識・テクニックをまとめていきたいと思います。
競馬予測が出力されるまで
データ収集から機械学習アルゴリズムによって予測が出力される過程は以下の図のように表されます。

競馬予測に必要なデータを集める
データの取得はデータ解析のまず始めに行なう作業です。データ提供サービスによって扱っているデータの種類や扱える環境、使用料金などが異なるので、よく調べておく必要があります。競馬データが取得できる主なサービスのそれぞれの特徴は以下の表の通りです。
| JRA-VAN DataLab. | netkeiba.com | JRDB | |
|---|---|---|---|
| 月額料金 | 2,052円 | 0〜934円 | 1,980〜2,480円 |
| 開発環境 | Windows・Visual Studio | なんでもOK | なんでもOK |
| 信頼度 | ◎ | ◯ | ◯ |
| データ種類 | ◯ | △ | ◎ |
| 手軽さ | △ | ◎ | ◯ |
| おすすめの人 | 本格的な運用を考える人・ オッズ解析がしたい人 |
安く手軽に競馬解析をしたい人 | 趣味〜本格的な運用をしたい人・ 豊富なデータで解析したい人 |
各サービスの詳細な解説は第3回理論記事をご覧下さい。
機械学習の入力となるデータを作成する
データ提供サービスから取得してきたデータを機械学習アルゴリズムに入力するには、適切なデータ成形をしなければなりません。ここでは競馬予測におけるデータ成形の方法について紹介します。
馬柱を作成する
競馬の1レースが持つ情報には、競馬場や距離などのレースに関する情報、出走する各馬の馬番、負担重量、騎手、プロフィール、過去戦績など多岐に渡ります。さらに過去戦績の中にもレース情報や騎手、着順などの情報が含まれており、複雑な構造をしています。そこでAlphaImpactでは、独自の『馬柱』データ構造を定義し、データの管理や生成の効率化を実現しています。馬柱は以下の要素から成っています。
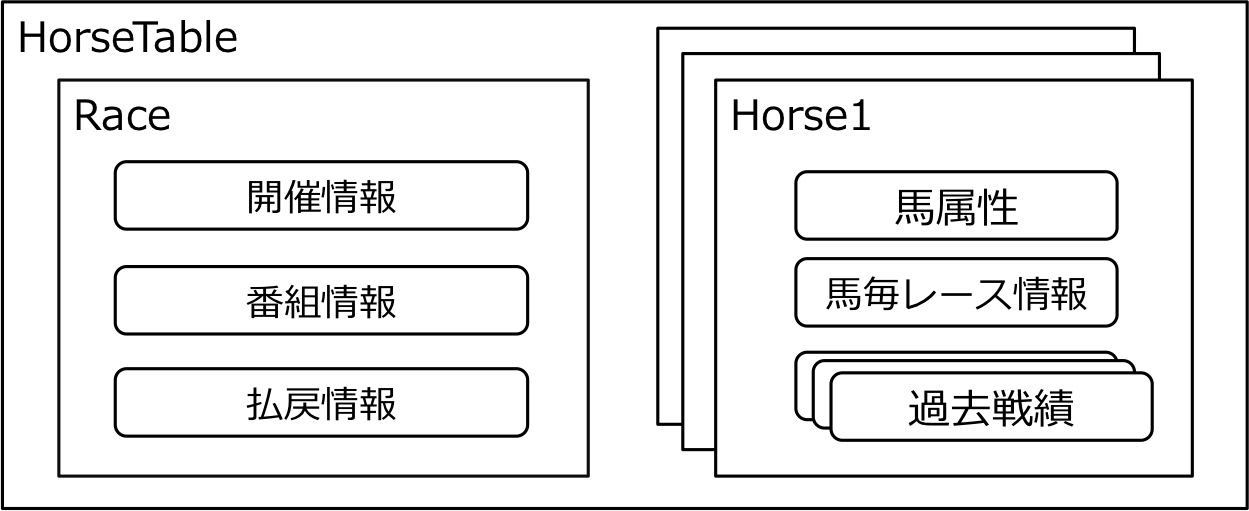
馬柱データ構造の詳細な解説は第4回理論記事をご覧ください。
特徴量の作成
機械学習アルゴリズムによって競馬予測を行なうとき、競走馬の情報はその馬の性別や馬体重、コースの距離などを定量化した特徴量として表されます。特徴量はそのデータのアイデンティティを決定づける量であるため、良い特徴づけができなければどれだけ優れたアルゴリズムを使っても精度は上がりません。例えば、性別や血統登録番号など数値自体に意味の無いカテゴリデータをダミー化するなどの工夫をしなければなりません。
特徴量の作り方の解説は第5回理論記事をご覧下さい。
データの前処理
作成した特徴ベクトルをそのまま機械学習アルゴリズムに入力することは可能です。しかし、精度を追求するには機械学習のアルゴリズムが扱いやすいように前処理をする必要があります。競馬のデータには年齢、タイム、距離、賞金など様々なスケールをもつデータが含まれていますが、そのように値の大きさが特徴量ごとに異なるようなデータは多くのアルゴリズムにおいて精度低下を招きます。それらのデータを正規化や標準化によってスケールを整えるという処理を加えるだけで、精度を大きく改善できる場合があります。
データの前処理の詳細な解説は第6回理論記事をご覧下さい。
分類問題と回帰問題
機械学習アルゴリズムの中で既知の事象のパターンを学習して未知の事象を予測する手法を教師あり学習と呼びます。教師あり学習では、勝ち/負けや1着/2着/3着/着外のようなクラスラベルを予測する分類問題と走破タイムのような連続値を予測する回帰問題を解くことができます。
競馬予測を分類問題として解く場合は以下のような問題設定が考えられます。
- 1着かどうかの予測
- 複勝圏内かどうかの予測
- 1着からの着差が0.1秒以内かどうかの予測
- 1着/2着/3着/着外の予測
- 着順上位(1
3着)/中位(47着)/下位(8~)の予測
また、回帰問題として解く場合は以下のような問題設定が考えられます。
- 走破タイムの予測
- 走破速度の予測
- スピード指数の予測
- 着順の予測
このように一口に競馬予測といっても、その目的によって何を予測するかは適切に選択する必要があります。例えば、目的変数をうまく設定することで『横山典弘騎手がポツンするかどうか』を予測することも可能です。
分類問題と回帰問題の解説については第7回理論記事をご覧下さい。
これまで紹介した機械学習アルゴリズム
機械学習アルゴリズムには様々な手法が提案されており、解く問題、データの性質、データ量などから適切なアルゴリズムを選択する必要があります。これまで紹介した手法の特徴を以下の表にまとめました。
| モデル | 分類 | 回帰 | 精度 | 学習時間 | 非線形 | 備考 |
|---|---|---|---|---|---|---|
| 線形モデル | × | ◯ | △ | ◎ | × | |
| ロジスティック回帰 | ◯ | × | △ | ◎ | × | |
| SVM | ◯ | ◯ | ◯ | ◯ | ◯ | 特徴次元数が大きい時にも有効 |
| 決定木 | ◯ | ◯ | ◯ | ◯ | ◯ | スケールに影響されない・意味解釈性に優れている |
| ランダムフォレスト | ◯ | ◯ | ◎ | ◯ | ◯ | スケールに影響されない・過学習しにくい |
各手法の解説はそれぞれ以下のページでご覧下さい。
ジャパンカップの予測
過去記事で紹介した機械学習アルゴリズムによる2016年ジャパンカップの予測結果をまとめました。
複勝分類
各モデルで出走馬が複勝圏内に入るか否かの2値分類問題を学習した分類モデルによる予測順位です。
| 着順 | 馬番 | 馬名 | LR | SVM | 決定木 | RF | 人気 |
|---|---|---|---|---|---|---|---|
| 1 | 1 | キタサンブラック | 1 | 1 | 1 | 1 | 1 |
| 2 | 12 | サウンズオブアース | 3 | 4 | 2 | 7 | 5 |
| 3 | 17 | シュヴァルグラン | 5 | 5 | 2 | 2 | 6 |
| 4 | 3 | ゴールドアクター | 4 | 6 | 2 | 5 | 3 |
| 5 | 16 | リアルスティール | 2 | 2 | 2 | 4 | 2 |
| 6 | 14 | レインボーライン | 6 | 3 | 2 | 6 | 8 |
| 7 | 5 | イキートス | 17 | 17 | 15 | 15 | 16 |
| 8 | 7 | ワンアンドオンリー | 13 | 10 | 15 | 13 | 14 |
| 9 | 4 | ルージュバック | 10 | 11 | 2 | 10 | 7 |
| 10 | 6 | ラストインパクト | 8 | 7 | 13 | 12 | 13 |
| 11 | 10 | トーセンバジル | 7 | 8 | 2 | 3 | 12 |
| 12 | 15 | ナイトフラワー | 12 | 13 | 2 | 11 | 9 |
| 13 | 9 | ディーマジェスティ | 9 | 9 | 2 | 8 | 4 |
| 14 | 8 | イラプト | 14 | 14 | 15 | 14 | 10 |
| 15 | 13 | ヒットザターゲット | 15 | 15 | 13 | 17 | 17 |
| 16 | 2 | ビッシュ | 11 | 12 | 2 | 9 | 11 |
| 17 | 11 | フェイムゲーム | 16 | 16 | 12 | 16 | 15 |
タイム回帰
各モデルで出走馬の走破タイム回帰を学習した回帰モデルによる予測順位です。
| 着順 | 馬番 | 馬名 | 線形回帰 | SVM | 決定木 | RF | 人気 |
|---|---|---|---|---|---|---|---|
| 1 | 1 | キタサンブラック | 1 | 7 | 1 | 1 | 1 |
| 2 | 12 | サウンズオブアース | 7 | 8 | 1 | 3 | 5 |
| 3 | 17 | シュヴァルグラン | 5 | 4 | 7 | 5 | 6 |
| 4 | 3 | ゴールドアクター | 9 | 1 | 5 | 6 | 3 |
| 5 | 16 | リアルスティール | 3 | 2 | 7 | 2 | 2 |
| 6 | 14 | レインボーライン | 2 | 14 | 10 | 10 | 8 |
| 7 | 5 | イキートス | 17 | 17 | 15 | 17 | 16 |
| 8 | 7 | ワンアンドオンリー | 11 | 10 | 10 | 16 | 14 |
| 9 | 4 | ルージュバック | 12 | 12 | 10 | 8 | 7 |
| 10 | 6 | ラストインパクト | 10 | 3 | 10 | 9 | 13 |
| 11 | 10 | トーセンバジル | 6 | 6 | 1 | 4 | 12 |
| 12 | 15 | ナイトフラワー | 15 | 11 | 15 | 12 | 9 |
| 13 | 9 | ディーマジェスティ | 4 | 5 | 5 | 7 | 4 |
| 14 | 8 | イラプト | 16 | 13 | 15 | 13 | 10 |
| 15 | 13 | ヒットザターゲット | 14 | 9 | 7 | 15 | 17 |
| 16 | 2 | ビッシュ | 8 | 15 | 10 | 11 | 11 |
| 17 | 11 | フェイムゲーム | 13 | 16 | 1 | 14 | 15 |
※ 表中のモデルの略名はLR→ロジスティック回帰、SVM→サポートベクターマシン、RF→ランダムフォレストを表しています。
おわりに
今回は競馬予測のスタートラインとなるデータ収集から機械学習アルゴリズムまでをおさらいしました。ここまで辿り着くのに約5ヶ月ほど経ってしまいましたが、これは競馬予測のほんの一端であり、まだまだ伝えきれていないことがたくさんあります。次回はいよいよディープラーニングによる競馬予測について解説していきます。今後も引き続き理論記事をお楽しみ下さい。